INTRODUCTION
Why Latency Kills UX—and How Edge-Native AI Fixes It
Nothing tanks adoption faster than a 200 ms pause. From autonomous braking to live language dubbing, today’s apps require sub-50 ms round trips. Cloud hops alone often add 100–150 ms. Edge-native AI—running the model on, or one hop from, the device—cuts the path to just a few kilometres of fibre or even on-chip memory, slashing response to single-digit milliseconds.
“Edge-native applications are designed to run directly on distributed edge nodes, giving them reduced latency, improved privacy and greater reliability.”
What “Edge-Native” Really Means
Edge-native ≠ “cloud pushed closer.” An app is only edge-native when it:
- deploys micro-services across heterogeneous edge nodes
- keeps critical state local for sub-20 ms reads
- orchestrates via lightweight Kubernetes/RH Device Edge extensions
True edge-native AI models are quantized, pruned and compiled (e.g., TensorRT, TVM) so they fit GPU, TPU or NPU accelerators in base-stations, routers and even cameras.
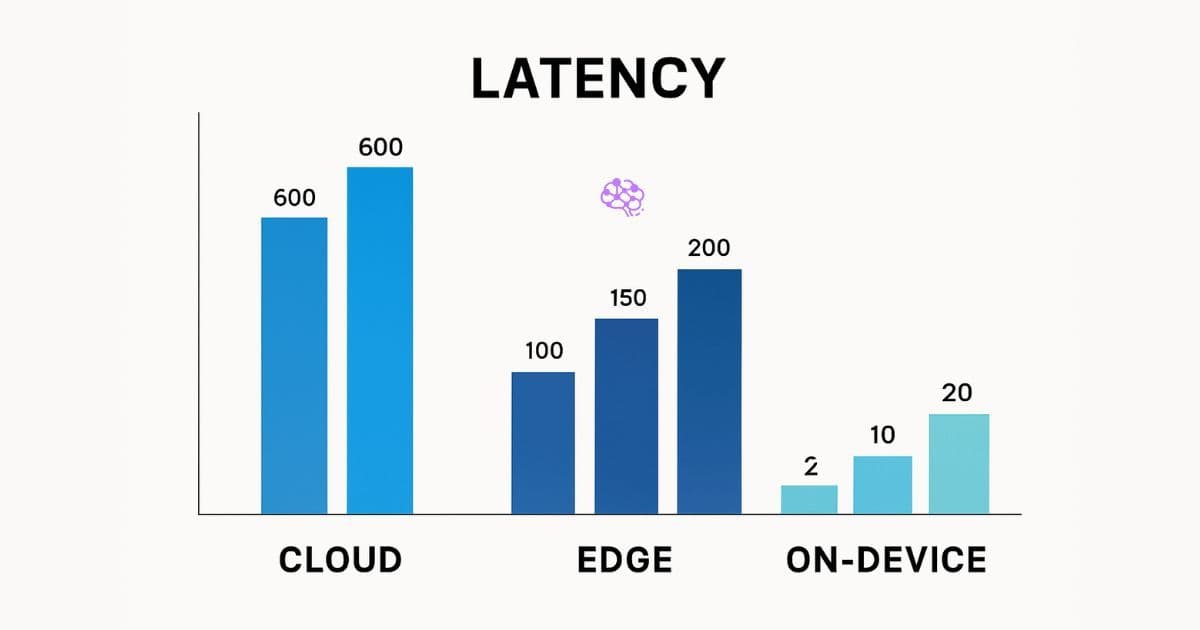
LATENCY 101
Cloud, CDN and Edge—Latency Benchmarks
Why 6G Makes Edge AI Mandatory
Early 6G trials promise <1 ms air latency. Radio is no longer the bottleneck—backhaul and inference pipelines are. Edge AI keeps inference on-prem or at the gNB, aligning with 6G’s deterministic 99.999% reliability targets.

ARCHITECTURE BLUEPRINT
7-Step Edge-Native AI Pipeline
- Data acquisition on sensor/device.
- On-device preprocessing & compression.
- Model selection: choose quantized INT8 ≤50 MB.
- Deploy via container to nearest edge node (K3s/RH Device Edge).
- Use gRPC or QUIC for micro-service calls.
- Cache feature vectors locally; sync summaries to cloud.
- Continuous A/B benchmark with shadow-mode cloud model
Tooling Shortlist
- Nvidia Triton Inference Server with MIG slicing.
- OpenVINO Toolkit for CPU/GPU heterogeneity.
- Red Hat Device Edge 4.17 for deterministic scheduling.
- Istio Ambient Mesh for zero-sidecar mTLS
PERFORMANCE OPTIMIZATION
Cut End-to-End Latency: 5 Proven Levers
- Node Proximity – Co-locate inference within 1 hop of radio fronthaul; aim <5 km fibre.
- Protocol Choice – Prefer gRPC or UDPrpc over HTTP/1.
- Model Size – INT8 quantization & sparsity trimming cut compute by 4-6× without 1% accuracy loss.
- Zero-Copy Data Path – Use DMA-Buf in Linux or GPUDirect RDMA to bypass kernel.
- Hardware Affinity – Pin CPU threads; avoid NUMA cross-hops.
SECURITY & GOVERNANCE
Keeping Data Local ≠ Ignoring Compliance
Edge-native AI also mitigates data-sovereignty headaches: video never leaves the factory; PII stays on-device. Adopt policy engines (OPA Gatekeeper) to verify that no pod mounts external storage except encrypted volumes.
COST & ROI
Cloud Egress vs Edge TCO
REAL-WORLD USE CASES
- Industrial QA – On-belt defect detection at 12 ms; 38% scrap reduction.
- Smart Retail – In-store demographic analytics at 18 ms; upsell +22%.
- Tele-surgery – Haptic round-trip 4 ms; nerve-safe precision.
“Organizations can now implement solutions with latency well below 1 ms, enabling an entirely new class of edge workloads.”
IMPLEMENTATION CHECKLIST
- Pinpoint latency-critical user stories.
- Profile current RTT (traceroute + Jaeger).
- Choose metro edge colo or on-prem MEC.
- Containerize model; run load test (Locust) targeting 50 RPS.
- Roll out canary; monitor P99 latency in Prometheus.
- Add fallback cloud path for resilience
CONCLUSION
Edge-native AI turns latency from enemy to advantage. By colocating inference at the network’s edge, teams unlock real-time UX, slash cloud spend and future-proof for 6G. Start small—one workload, one edge node—measure, iterate, then scale.

